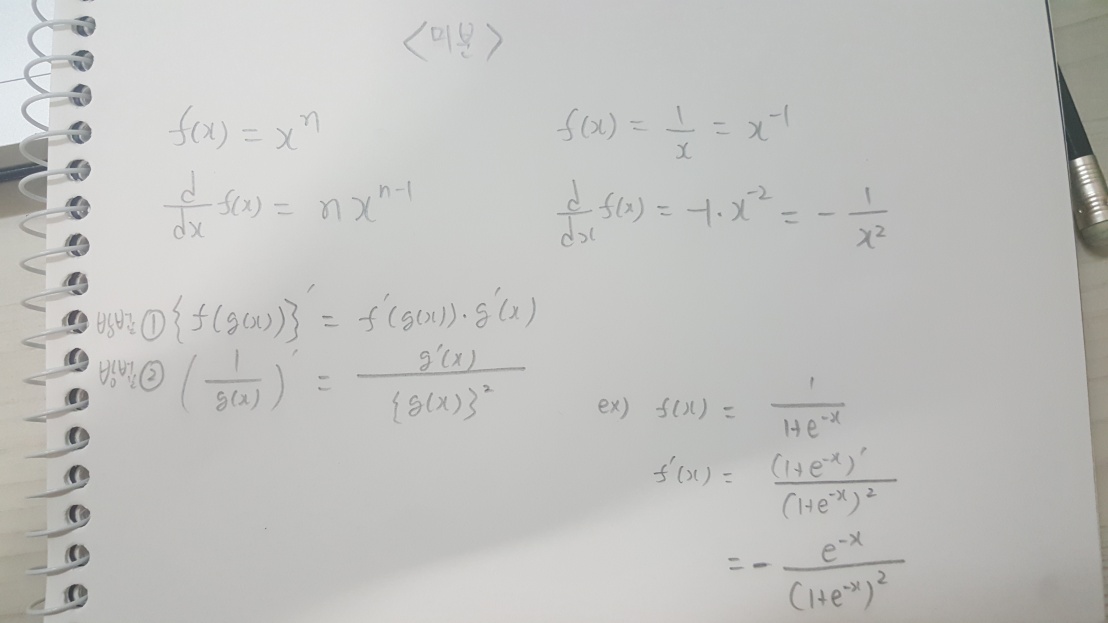
Category: statistics&math
앙상블 기법
앙상블 기법은 이진트리로 구성된 여러개의 트리를 만들고 각 트리의 결과를 조합해 결과를 하나로 합치는 것을 말하며 크게 아래의 3가지 알고리즘이 존재한다.
- 부트스트랩 애그리게이션(배깅) 알고리즘
- 그래디언트 부스팅 알고리즘
- 랜덤 포레스트 알고리즘
배깅과 랜덤 포레스트는 훈련데이터의 부분집합으로 훈련시킴을 통해 분산을 최소화 하는방식으로 접근하며 그래디언트 부스팅은 훈련데이터 모두로 훈련시킴을 통해 오차 최소화로 접근한다.
# 배깅 알고리즘
- 테스트 데이터를 제외한 원 데이터에서 임의 복원 추출 방식(중복인 데이터 행이 존재할 수 있음)으로 동일한 크기의 여러개 데이터 셋을 만들어주고 이 각각의 데이터로 훈련시킨 예측모델(의사결정트리)을 여러개 만들어 각 모델의 결과값에 대하여 회귀모형일때는 평균, 분류모형일때는 과반수 투표로 최종 결과를 반환해주는 방식.
- 배깅 방식은 단순하지만 예측 모델의 분산을 줄여 줌으로써 불안정한 학습방법의 예측력을 획기적으로 향상시킨다.
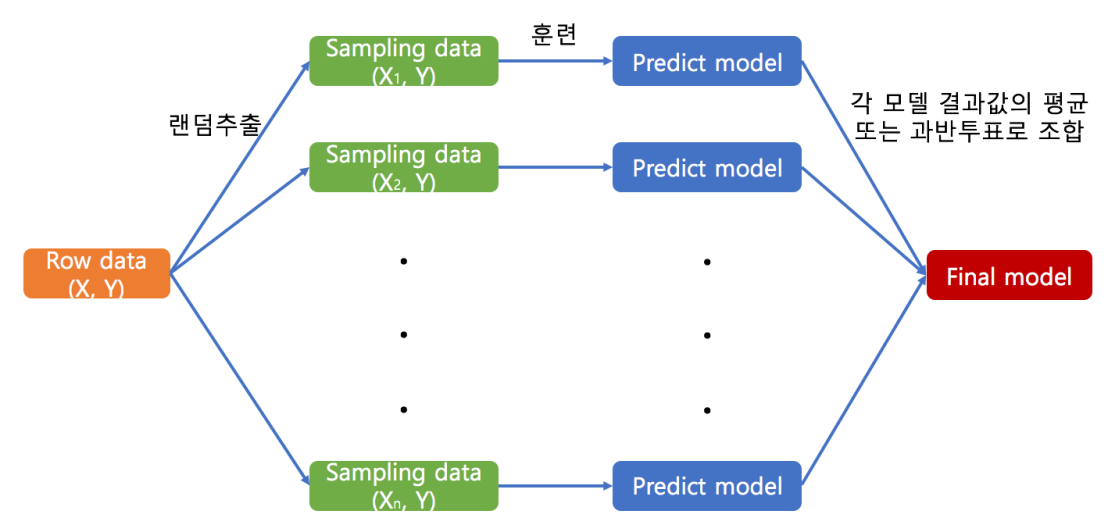
# 그래디언트 부스팅 알고리즘
- 배깅과 다르게 샘플데이터를 분할하지 않고 테스트 데이터를 제외한 원 데이터 전체로 첫 모델 만드는 것을 시작하고, X값은 모든 모델 훈련시 동일한 것을 사용하며 타깃값을 계속해서 갱신해주고 그것으로 각각의 예측모델을 생성한다.
- 잔차(residuals)갱신이란?
이전 잔차(최초엔 Y) – (eps * 이전 예측모델의 예측값) 값을 다음의 타깃 값으로 사용하는 것. - 다른 알고리즘과 비교해 구분되는점은 개별 기본 학습자를 훈련시킬때 이용하는 target값을 모든 선행 기본 학습자에서 누적된 오차를 이용한다는 점(선행 학습자에 대해 의존적)에서 다르다.
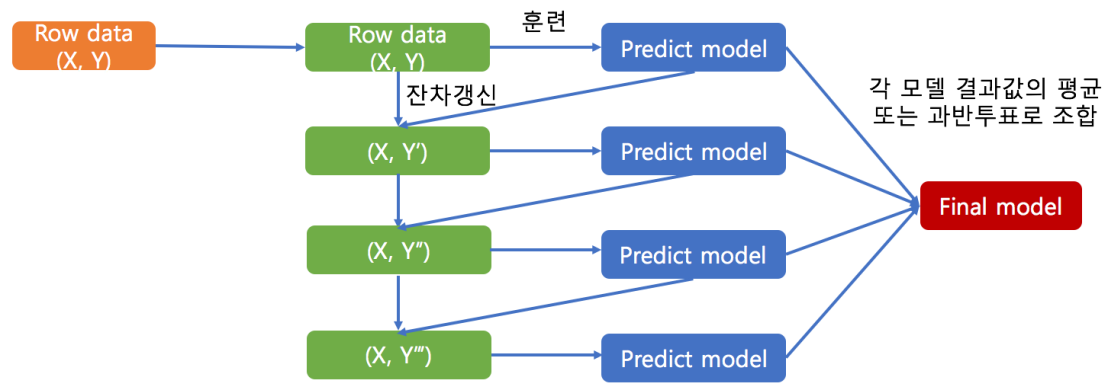
# 랜덤 포레스트
- 한마디로 표현하면 배깅의 방법에서 임의 속성 선택을 추가한 것이 랜덤 포레스트가 되겠다. 좀더 자세히 설명하자면 테스트 데이터를 제외한 원 데이터에서 샘플데이터를 만드는 방법은 각 샘플이 서로 다른 속성을 같은 개수로 비복원 랜덤추출로 선택하고 행은 배깅과 같게 복원 랜덤추출로 선택하여 이에 대한 데이터 세트로 각각의 예측모델을 훈련시킨다.
- 다른 알고리즘과 비교해 구분되는점은 선행 학습자의 결과를 기다려야하는 그래디언트 부스팅과 다르게 각 훈련을 병렬로 처리할 수 있다는 장점이 있다.
모델의 성능 시뮬레이션
보통 2/3의 데이터로 훈련시키고 나머지 1/3로 성능을 측정한다.
그런데 검증하는 방식에는 여러가지 방법이 있다.
N-폴트 교차 검증
- 예시)
전체 데이터를 4개로 나눈 뒤 첫 실험에서는 첫번째 1조각을 테스트 데이터로 남겨두고 나머지 3개의 조각으로 훈련을 시킨다.
두번째 실험에서는 두번째 1조각을 테스트 데이터로 남겨두고 나머지 3개의 조각으로 훈련을 시킨다…. 이렇게 마지막 조각까지 성능을 쭉 테스트 해본다. - 단점으로 n개의 조각만큼 반복해야하므로 시간이 오래걸린다는 점이 있음
테스트를 마쳤다면 모델 트레이닝에 사용한 데이터와 테스트에 사용한 두 데이터 모두를 이용하여 더 큰 데이터로 훈련을 시켜줘야 정확도가 높아진다.
예측 모델의 성능 측정하기(분류문제의 경우)
분류문제에 접근하는 방법은 정확하게 분류하지 못한 관측치의 비율인 오분류 오차율을 관리하는 것이다. 분류문제의 경우 결정분기점의 값을 정하고 이에 따라 혼돈행렬을 작성한뒤 오분류 오차율을 구한다. 그리고 결정 분기점의 값을 0부터 1까지 사이의 값으로 수정해가며 오분류 오차율이 어떻게 변하는지 확인하여 오분류 오차율이 가장 낮은 결정분기점을 선택하여 성능을 최적화 할 수 있다.
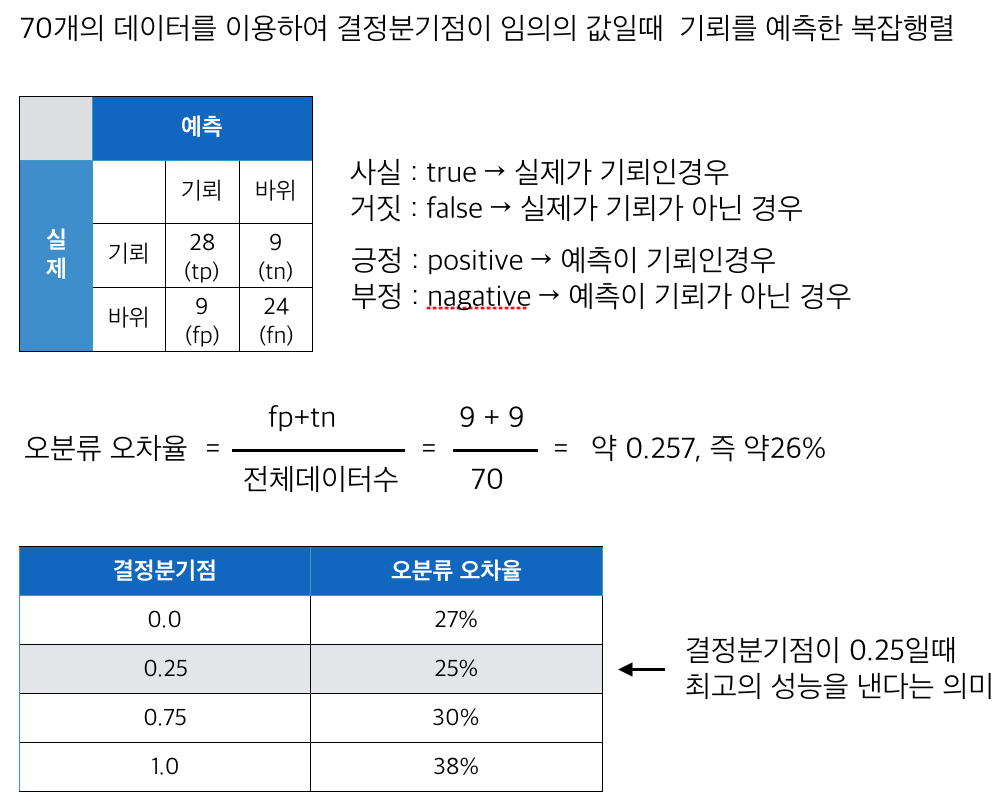
특수한 경우에 예측 실패시 발생하는 비용이 fp 와 tn의 경우 각각 다를경우가 있는데 이때는 결정분기점을 수정해가며 예측 실패시 발생하는 비용을 둘다 합산하여 최소한의 비용이 드는 결정분기점을 결정할 수도 있다.

위의 방법과 다르게 특정 결정 분기점의 오분류 오차를 사용하는 것 외에도 분류기의 전체적인 성능을 특성화 할 수 있는 기법이 있다. 그것은 바로 수신자 조작 특성(Receiver Operating Characteristic) ROC 곡선이다. ROC곡선은 사실긍정비율(TPR) 대비 거짓긍정비율( FPR)을 도표로 그린다.
TPR은 모든 긍정 표본 대비 정확하게 긍정으로 예측한 비율이고
FPR은 모든 오인 표본 대비 FP 총 개수이다.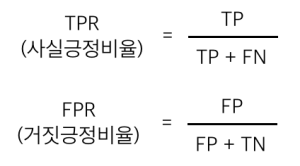
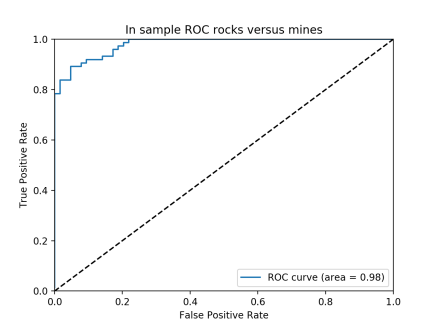
아래의 ROC차트는 왼쪽위 구석에 모여있어야 좋은 것이고 area(그래프 아래의 면적)가 1에 가까울 수록 성능이 좋은 것이다. 아래의 차트에서 표본내 데이터를 대상으로한 차트가 더 좋은것임을 알 수 있다.
<표본내 데이터 대상>
<표본외 데이터 대상>
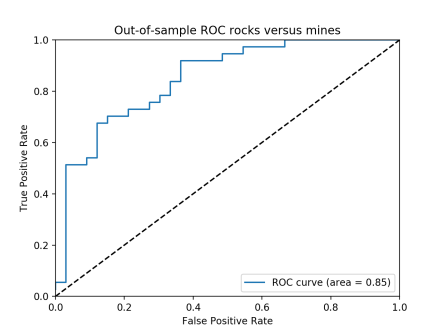
위에서 공부한 이항 분류 문제의 성능을 측정할 때 사용하는 몇몇 기법은 다중 분류 문제에서도 사용할 수 있다. 오분류 오차와 혼동행렬 두 가지 모두는 다중 분류 클래시파이어에 대해 잘 활용 할 수 있다. 그리고 ROC곡선과 AUC1의 다중클래스 일반화도 있다.
예측 모델의 성능 측정하기(회귀문제의 경우)
- 오차(Error)
– y : 실제 x에 대한 y값
– pred() : 속성 x를 이용해서 y를 예측한 값을 반환하는 함수
![]()
- 평균제곱오차(MSE, Mean Squared Error)
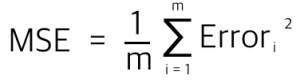
- 평균제곱근오차(RMSE, Root Mean Square Error)
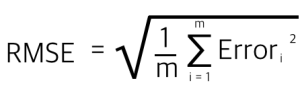
- 평균절대오차(MAE, Mean Absolute Error)
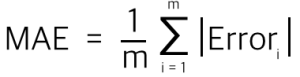
좋은 성능이라고 하는 것은 속성 x를 이용하여 y에 근접한 예측을 만들어낸다는 것이다. y가 실수인 회귀분석 문제에서의 성능은 보통 계산할때 사용하기 편한 RMSE와 MAE를 사용한다.
성능을 측정하는 방법을 예를들면,
성능이 좋지 않은 경우
- MSE가 타깃의 분산과 비슷한경우
- RMSE가 타깃의 표준편차와 비슷한 경우
성능이 좋은 경우
- RMSE가 타깃의 표준편차가 각각 1.65와 2.75로 반 정도라면 이는 상당히 높은 성능임
위와같은 오차에 대한 기초 통계량을 계산하지 않더라도 오차의 히스토그램, 사분위수나 십분위수 경계의 말단 행동, 정상분포도 등을 이용하면 오차의 원인이나 정도를 분석하는데 유용하다. 때로는 이러한 조사가 오차 원인을 찾거나 잠재적 성능 개선을 할 수 있는 인사이트를 제공한다.
분산과 표준편차(variance&standard deviation)
편차 : 기댓값 혹은 평균으로부터 얼마나 떨어져 있는가
분산 : 기댓값 혹은 평균으로부터 다른것들이 얼마나 떨어져 있는가를 나타내는 수들의 제곱의 평균
표준편차 : 분산이 나타내는 수가 너무 커서 와닿지 않으므로 분산에 루트 씌운 값
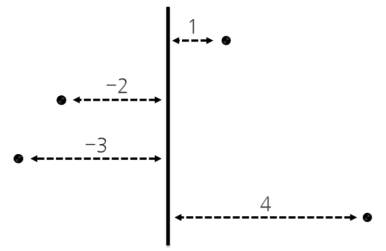 출처: http://math7.tistory.com/16
출처: http://math7.tistory.com/16

