# Machine Learning Algorithm의 성능이 떨어질 때 할 수 있는 조치

위의 부분에서 교수님은 머신러닝 시스템의 성능을 향상시키고자 할 때 우리가 무엇을 시도할 수 있고, 시도할 수 있는 것 중에서 무엇을 우선적으로 시도해야 하는 지에 대해 설명한다.
성능을 향상시켜야 하는 경우의 예시를 들어줬는데 만약 내가 집값을 예측하는 regularization linear regression을 구현했다고 가정해보자. 그런데 새로운 data set을 그 hypothesis에 넣어서 확인해보니 너무 큰 에러가 발생했다. 이럴때 어떻게 해야겠는가?를 묻는다.
<만약 이런 경우 시도할 수 있는 것>
- 더 많은 훈련 예제(훈련 데이터)들을 수집한다.
– 전화 설문조사 또는 방문조사를 실시하여 각각의 집들이 얼마의 가격을 형성하고 있는지 더 많은 데이터를 수집한다.
– 더 많은 데이터를 수집하는 것이 성능을 향상시키는데 도움이 될 수 있으나 가끔은 더 많은 데이터를 얻는 것이 실제로 도움이 되지 않을 때도 있다. - Overfitting을 피하기 위해 사용 features를 줄여본다.
- 도메인에 대한 세부조사를 통하여 새로운 feature를 얻어본다.
- Polynomial features을 추가해본다.
– x1^2, x2^2, x1x2 등등 - regularization 변수 람다의 값을 감소시켜본다.
- regularization 변수 람다의 값을 증가시켜본다.
이렇게 6가지 정도의 선택권이 있는데 우리는 감으로 1개를 골라 무작위로 시도해 볼 수 있을 것이다. 그러나 이 방법은 좋지 않다. 왜냐하면 지표없이 접근하는 것이기 때문에 무작위로 선택해 처음 시도했던 방법으로 인해 프로젝트의 기간만 연장되는 결과가 될 수 있다. 따라서 우리는 다음 진도에서 ‘Diagnostic(진단)’이라는 것을 배우게 될 것이다.
Diagnostic은 알고리즘의 성능을 향상시키기 위해 뭘 해야하는지에 대해 통찰력을 얻을 수 있는 테스트를 말한다. 이것이 직감적으로 선택하는 것에 대한 문제를 방지해 줄 것이다.
# Hypothesis의 성능을 평가하는 방법
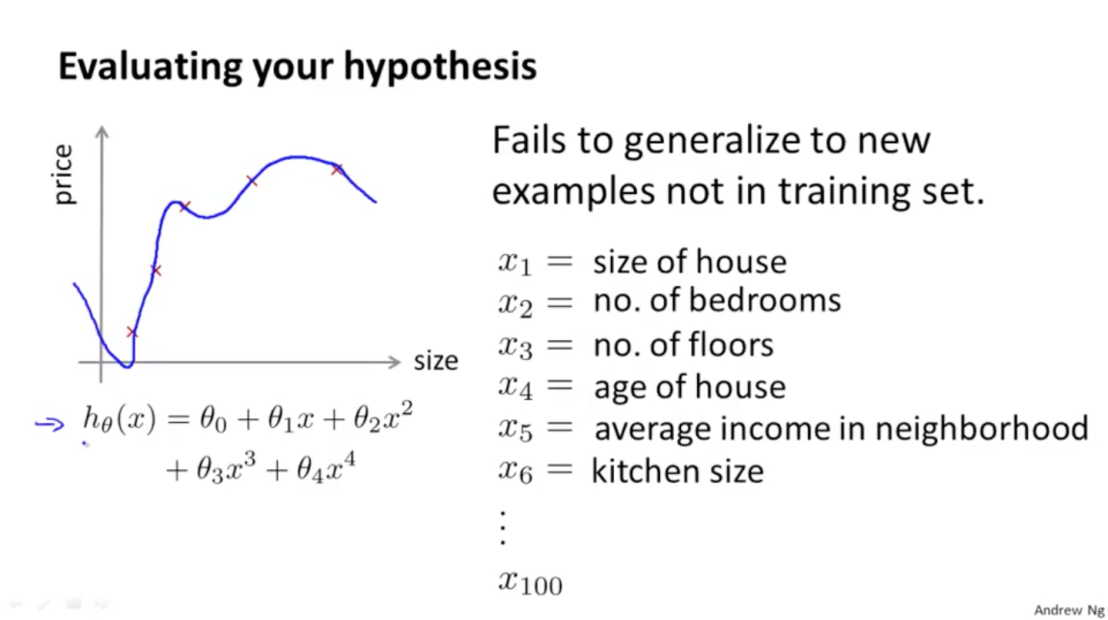 hypothesis를 평가할 때 위의 사진처럼 그래프를 그려 확인해 볼 수 있지만 만약 입력 features가 너무 많은 경우 그래프로 그려서 확인하기 힘들 수 있다. 따라서 이 때는 비용함수의 값을 통해 에러를 확인한다.
hypothesis를 평가할 때 위의 사진처럼 그래프를 그려 확인해 볼 수 있지만 만약 입력 features가 너무 많은 경우 그래프로 그려서 확인하기 힘들 수 있다. 따라서 이 때는 비용함수의 값을 통해 에러를 확인한다.

훈련시킨것에 대한 평가를 하려면 전체 Data set으로 파라미터인 세타를 훈련시키면 안된다. 파라미터 세타를 훈련시키기전 전체 데이터를 먼저 랜덤하게 정렬하고 Training set 70%, Test set 30%로 나눠주는 작업이 필요하다. 다음은 Linear Regression과 Logistic Regression에서 hypothesis를 평가는 방법을 세부적으로 알아본다.
 위의 사진은 선형회귀를 위한 훈련/테스트 절차에 관한 내용이다.
위의 사진은 선형회귀를 위한 훈련/테스트 절차에 관한 내용이다.
- Training set으로부터 비용함수를 최소화 하는 방향으로 파라미터 세타를 학습한다.
- Test set을 비용함수에 넣어 에러를 계산한다.

위의 사진은 로지스틱 회귀를 위한 훈련/테스트 절차에 관한 내용이다.
- Training set으로부터 비용함수를 최소화 하는 방향으로 파라미터 세타를 학습한다.
- Test set을 비용함수에 넣어 에러를 계산한다.
- Multiclassification인 경우 대안적인 방법이 존재하는데 예측을 정확하게 한 것의 개수와 틀린 개수의 비율로 에러를 알 수 있다.
#
